大数据ETL
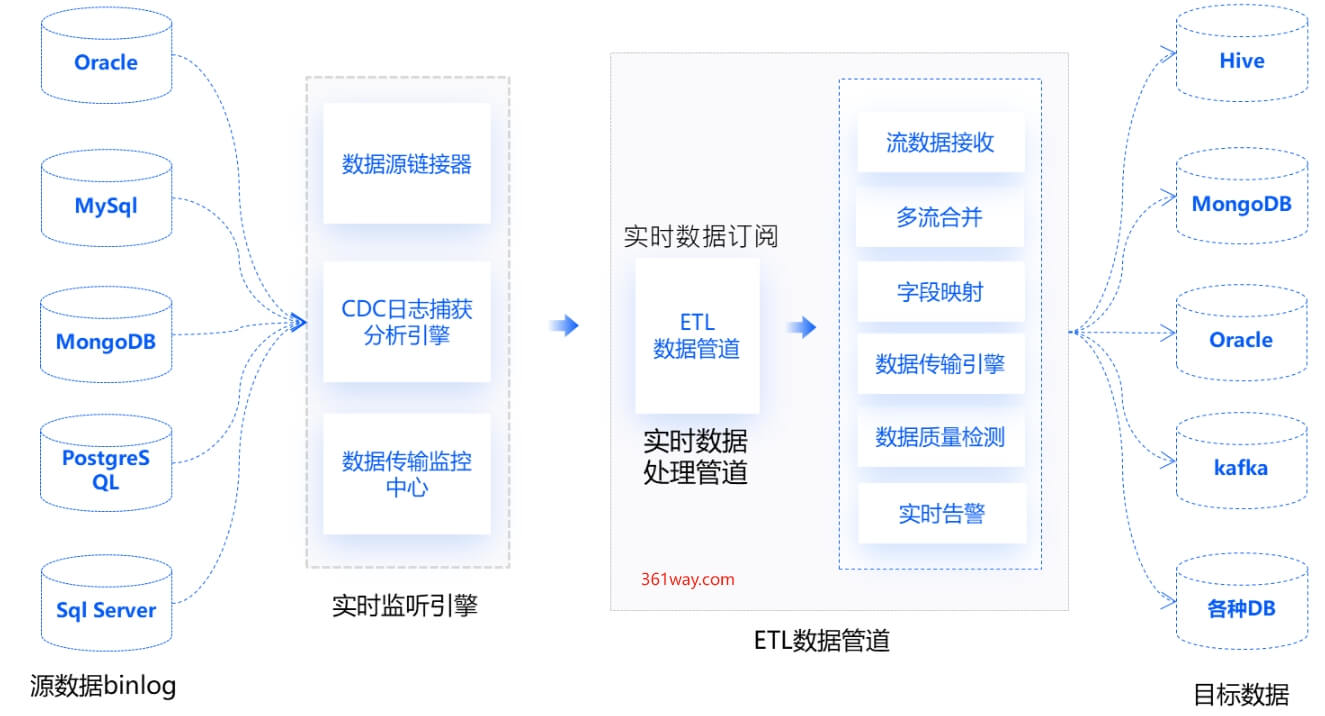
大数据抽取、加载和转换工具(ETL,Extract, Transform, Load)是处理、转换和集成大规模数据的关键工具。




以下是常见的大数据ETL工具:
1. 抽取(Extract)工具
- Apache Sqoop:主要用于从关系型数据库(如MySQL、PostgreSQL、Oracle等)抽取数据,并将其导入到Hadoop等大数据平台。
- Apache Flume:适用于从不同的来源(如日志文件、网络流等)实时收集数据并传输到Hadoop等分布式存储系统。
- Talend:支持从各种数据源(关系型数据库、云平台、文件系统等)抽取数据,并具备强大的集成能力。
2. 加载(Load)工具
- Apache Kafka:一种分布式消息系统,支持高吞吐量的数据流传输,常用于将实时数据加载到Hadoop、Spark等大数据平台。
- Apache Nifi:提供数据流管理和自动化工具,可以从不同的数据源加载数据到目标系统,支持图形化界面。
- AWS Glue:适用于在AWS平台上加载和转换数据,支持从S3、Redshift、RDS等AWS服务加载数据。
3. 转换(Transform)工具
- Apache Spark:一个强大的分布式计算引擎,支持大规模数据的实时处理和转换,支持Python、Java、Scala等多种编程语言。
- Apache Hive:基于Hadoop的数据仓库工具,提供SQL-like的查询语言,可以进行大数据的批量处理和转换。
- Pentaho Data Integration (kettle PDI):提供数据清洗、转换和整合功能,支持ETL流程的可视化开发。
综合性ETL工具
- Informatica:一个功能全面的数据集成工具,支持数据抽取、转换和加载,常用于企业级数据仓库构建。
- Talend:不仅支持数据抽取,还可以进行复杂的数据转换和加载,广泛支持不同的数据源和目标系统。
- Microsoft SSIS (SQL Server Integration Services):用于构建数据集成和工作流应用,主要用于Microsoft SQL Server环境中的ETL过程。
这些工具适用于不同的数据类型和场景,具体选择取决于你的业务需求和技术栈。
捐赠本站(Donate)

如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))